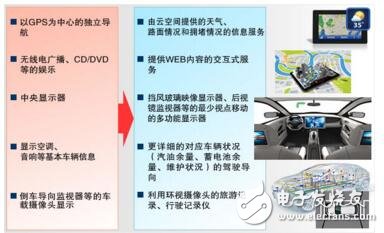
雖然是EDA公司收購IC設計IP,但此次收購可能會在整個競爭格局中產生連鎖反應。Cadence強化一站式服務和EDA工具護城河,而Arm轉向更高利潤的芯片設計。
關鍵字:
Artisan Arm Cadence IP
摘要本文介紹了一種在FPGA中實現的增強型正交頻分復用(OFDM)調制器設計,它使用了逆FFT模式的萊迪思快速傅立葉變換(FFT)Compiler IP核和萊迪思有限脈沖響應(FIR)濾波器IP核。該設計解決了在沒有主控制器的情況下生成復雜測試模式的常見難題,大大提高了無線鏈路測試的效率。通過直接測試模擬前端的JESD204B鏈路,OFDM調制器擺脫了對主機控制器的依賴,簡化了初始調試過程。該設計可直接在萊迪思FPGA核中實現,從而節省成本并縮短開發周期。該調制器的有效性驗證中使用了Avant-X70 V
關鍵字:
萊迪思半導體 iFFT FIR IP 5G OFDM
本周,Nvidia 及其合作伙伴 Amkor、富士康、SPIL、臺積電和緯創軟件宣布計劃在未來四年內在美國建造價值 5000 億美元的 AI 硬件。該公告包括實際 AI 處理器的生產、測試和包裝,以及組裝實際的 AI 服務器。但是,盡管該公告代表了構建價值五萬億美元的 AI 硬件的計劃,但它缺乏細節,這讓人懷疑它是否能做到。因此,我們決定仔細研究一下。在美國構建本地 AI 供應鏈臺積電已經承諾在其 Fab 21 制造工廠投資 1650 億美元,時間未知,因此可以肯定地說,有(并且將有)
關鍵字:
美國制造 英偉達 服務器 GPU NVIDIA
為了提供更好的用戶體驗,包括高質量的視頻傳輸、更新的筆記本電腦(例如最新的 AI PC)和其他前沿設備,都需要 5 納米及以下的先進節點 SoC,以達成出色的功耗、性能和面積(PPA)目標。然而,隨著技術發展到 5 納米以下的工藝節點,SoC 供應商面臨各種挑戰,例如平衡低功耗和低工作電壓(通常低于 1.2V)的需求。與此同時,市場也需要高分辨率相機、更快的幀率和 AI 驅動的計算,這就要求接口具有更高的數據傳輸速率和更強的抗電磁干擾(EMI)能力。隨著這些性能要求變得越來越復雜,市場亟需創新的解決方案來
關鍵字:
Cadencee USB2V2 IP
創意2日宣布,自主研發的HBM4控制器與PHY IP完成投片,采用臺積電最先進N3P制程技術,并結合CoWoS-R先進封裝,成為業界首個實現12 Gbps數據傳輸速率之HBM4解決方案,為AI與高效能運算(HPC)應用樹立全新里程碑。HBM4 IP以創新中間層(Interposer)布局設計優化信號完整性(SI)與電源完整性(PI),確保在CoWoS系列封裝技術下穩定運行于高速模式。 創意指出,相較前代HBM3,HBM4 PHY(實體層)效能顯著提升,帶寬提升2.5倍,滿足巨量數據傳輸需求、功耗效率提升1
關鍵字:
創意 HBM4 IP 臺積電 N3P
4月3日消息,NVIDIA在官網表示,在最新的MLPerf V5.0基準測試中,NVIDIA的Blackwell平臺取得了令人矚目的成績。MLPerf是一個衡量人工智能硬件、軟件和服務性能的標準化基礎測試平臺,它由圖靈獎得主大衛·帕特森聯合谷歌、斯坦福、哈佛大學等頂尖企業和學術機構成立,是權威性最大、影響力最廣的國際AI性能基準測試。最新更新的MLPerf 添加了Llama 3.1 405B,這是最大和最難以運行的開放權重模型之一。NVIDIA表示,雖然許多公司在其硬件上運行MLPerf基準測試以衡量性能
關鍵字:
英偉達 GPU 計算平臺 Blackwell
盡管有嚴格的出口限制,以及面對價格暴跌的數據中心租賃價格,英偉達的H100 繼續穩定在中國市場出貨,當然如果我們更嚴謹一點,現在的主力產品是英偉達的H20。
關鍵字:
數據中心 GPU 英偉達
Supermicro, Inc.作為AI/ML、高效能計算、云端、存儲和5G/邊緣領域的全方位IT解決方案提供企業,近日宣布推出一系列工作負載優化GPU服務器和工作站,可支持全新NVIDIA RTX PROTM 6000 Blackwell服務器版GPU。Supermicro具備廣泛機型的服務器系列專為NVIDIA Blackwell PCIe GPU優化,助力更多企業通過加速型計算支持LLM推理與微調、代理式AI、可視化、圖形和渲染,以及虛擬化等應用。Supermicro多款GPU優化系統經NVIDIA
關鍵字:
Supermicro 企業級AI GPU
此前的GTC2025大會上,英偉達執行長黃仁勛公布了最新技術路線藍圖,令業界頗為期待。最新消息,臺積電將與英偉達合作,開發下代先進小芯片GPU,與英偉達“Rubin”架構發揮作用,為Blackwell架構的后繼者。據外媒Digital Trends報導,小芯片與傳統單晶片GPU差別很明顯,有更高性能、可擴展性和成本效率。小芯片使芯片商將多個較小半導體芯片封裝成單一芯片,提高產量,降低生產成本。這在半導體產業越來越受歡迎,芯片設計越來越復雜,傳統制程縮放局限性越來越大,借助臺積電封裝制程,英偉達可提高GPU
關鍵字:
英偉達 Rubin GPU 小芯片 臺積電
近日,一站式定制芯片及IP供應商——燦芯半導體(上海)股份有限公司宣布推出基于28HKD?0.9V/2.5V?平臺的DDR3/4, LPDDR3/4?Combo?IP?。該IP具備廣泛的協議兼容性,支持DDR3, DDR3L, DDR4和LPDDR3, LPDDR4協議,數據傳輸速率最高可達2667Mbps,并支持X16/X32/X64等多種數據位寬應用。燦芯半導體此次發布的DDR3/4,?LPDDR3/4 Combo IP集成高性能DDR&nb
關鍵字:
燦芯半導體 DDR3/4 LPDDR3/4 Combo IP
3月24日消息,據報道,甲骨文已與AMD簽署了一項價值數十億美元的協議,計劃搭建包含3萬塊MI355X的AI集群。甲骨文董事長兼CTO拉里·埃里森在2025財年第三財季電話會議上透露了這一采購計劃,埃里森還解釋了該公司優勢所在:“我們能打造比對手更快、更經濟的巨型 AI 集群。按小時計費模式下,速度優勢直接轉化為成本優勢,這正是我們斬獲大單的秘訣。”甲骨文計劃采用“小步快跑”的模式建設數據中心,先建小型數據中心,再根據需求逐步擴容。AMD MI355X對標英偉達B100/B200,預計2025年年中上市,
關鍵字:
甲骨文 AMD AI GPU
快科技3月19日消息,NVIDIA Blackwell架構雖然在加速卡、游戲卡上都遭遇諸多波折,但這并不影響NVIDIA對于未來的宏偉規劃,不但公布了下一代Rubin架構的具體產品規劃,還首次宣布了再下一代架構“Feynman”。Feynman就是理查德·費曼,美籍猶太裔人,20世紀最偉大的物理學家之一,諾貝爾物理學獎獲得者,在量子電動力學、量子計算、納米技術等領域都有開創性的成就,還撰寫了《費曼物理學講義》、提出了“費曼學習法”,1986年挑戰者號航天飛機爆炸失事的根本原因也是他查明的。NVIDIA這次
關鍵字:
英偉達 GPU 計算平臺
英偉達CEO黃仁勛最新表示,中國人工智能企業DeepSeek發布的R1模型只會增加對計算基礎設施的需求,因此,擔憂“芯片需求可能減少”是毫無根據的。當地時間周三(3月19日),黃仁勛在GTC大會與分析師和投資者會面時表示,外界先前對“R1可能減少芯片需求”的理解是完全錯誤的,未來的計算需求甚至會變得要高得多。今年1月時, DeepSeek發布的R1模型引發了市場轟動,該模型開發時間僅兩個月,成本不到600萬美元,僅用約2000枚英偉達芯片,但R1在關鍵領域的表現能媲美OpenAI的最強推理模型o1。這導致
關鍵字:
英偉達 GPU 計算平臺 AI DeepSeek
3月20日消息,英偉達CEO黃仁勛在開發者大會后接受采訪時表示,盡管英偉達的AI芯片價格昂貴,但它幫助你賺到的錢也是驚人的。此前在DeepSeek橫空出世后,展示了其產品在成本上的巨大優勢,當時投資者擔心這可能會降低對英偉達AI芯片的需求,于是開始拋售英偉達,英偉達市值曾一度蒸發近6000億美元。對此,黃仁勛承認“這些處理器和計算機非常昂貴” ,但他也補充說,之所以昂貴是因為英偉達的GPU是世界上最大、最復雜的芯片,制造成本非常高昂。他認為這些GPU能夠為用戶節省大量的時間和金錢,因為它們顯著減
關鍵字:
英偉達 GPU 計算平臺
gpu ip介紹
您好,目前還沒有人創建詞條gpu ip!
歡迎您創建該詞條,闡述對gpu ip的理解,并與今后在此搜索gpu ip的朋友們分享。
創建詞條
關于我們 -
廣告服務 -
企業會員服務 -
網站地圖 -
聯系我們 -
征稿 -
友情鏈接 -
手機EEPW
Copyright ?2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《電子產品世界》雜志社 版權所有 北京東曉國際技術信息咨詢有限公司
京ICP備12027778號-2 北京市公安局備案:1101082052 京公網安備11010802012473